머신러닝
FNN으로 이미지를 인식해보자 (딥러닝 레벨원)
- -
728x90
사전 정보
빛의 삼원색
RGB : 세 가지 색을 조합해 우리가 보는 컴퓨터 화면의 색상을 만든다.
그렇게 표현된 세가지 색상은 우리의 뇌가 받아들여 색을 인식한다.
우리가 보는 화면은 픽셀로 이루어져 있다.
우리가 현재 보는 화면은 사실 여러 개의 점이 모여 하나의 화면을 이루고 있다.
컴퓨터는 사실 3차원으로 우리가 보는 화면을 구성한다.
우리의 퍼셉트론은 어떻게 이 사진을을 이해하는가.

하나의 화면을 여러개로 잘라 1차원 데이터로 바꾼다.
위 사진처럼 7이라는 모습도 결국 잘라서 1차원 데이터로 만든다.
그러면 손글씨를 인식하는 머신러닝 코드를 살펴보자.
from tensorflow import keras # TensorFlow 라이브러리에서 Keras 모듈을 불러옵니다.
import data_reader # data_reader 파일에서 데이터 읽기 함수를 불러옵니다.
EPOCHS = 20 # 모델을 몇 번 학습시킬 것인지 정하는 에포크 수입니다. 기본값은 20입니다.
# 데이터를 읽어옵니다. data_reader 파일의 DataReader 클래스를 사용해 훈련/테스트 데이터를 로드합니다.
dr = data_reader.DataReader()
# 인공신경망 모델을 제작합니다. 28x28 입력 크기, 두 개의 Dense 레이어를 가지고 있습니다.
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)), # 입력 레이어, 28x28 데이터를 1차원으로 평탄화합니다.
keras.layers.Dense(128, activation='relu'), # 첫 번째 은닉 레이어, 128개의 뉴런과 ReLU 활성화 함수를 사용합니다.
keras.layers.Dense(10, activation='softmax') # 출력 레이어, 10개의 뉴런과 Softmax 활성화 함수를 사용합니다.
])1. 에포크 : 에포크는 전체 훈련 데이터셋에 대해 한 번 학습하는 과정을 의미합니다. 예를 들어, 에포크가 20이라면, 전체 훈련 데이터를 20번 반복해서 모델을 학습시킵니다. 더 많은 에포크는 모델이 데이터에서 더 복잡한 패턴을 학습할 수 있게 해 주지만, 너무 많은 에포크는 과적합(overfitting) 문제를 일으킬 수 있습니다.
2. Keras : 오픈 소스 신경망 라이브러리로, 인공 신경망 모델을 쉽고 빠르게 개발할 수 있도록 도와줍니다. 텐서플로우와 같은 저수준 라이브러리 위에서 동작하며, 코드를 단순화하고 가독성을 높여줍니다. 복잡한 딥러닝 모델도 상대적으로 적은 코드로 구현할 수 있게 해줍니다.
# 인공신경망을 컴파일합니다. 손실 함수와 최적화 알고리즘, 평가 메트릭을 지정합니다.
model.compile(optimizer='adam', metrics=['accuracy'],
loss='sparse_categorical_crossentropy')
# 인공신경망을 학습시킵니다. 훈련 데이터와 검증 데이터를 사용하며, 조기 중단 기능도 포함합니다.
print("\n\n************ TRAINING START ************ ")
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(dr.train_X, dr.train_Y, epochs=EPOCHS,
validation_data=(dr.test_X, dr.test_Y),
callbacks=[early_stop])
# 학습 결과를 그래프로 출력합니다. data_reader 파일의 draw_graph 함수를 사용해 결과를 시각화합니다.
data_reader.draw_graph(history)3. 인공신경망 컴파일 하기
- model.compile(optimizer ='adam', metrics =['accuracy'], loss='sparse_categorical_crossentropy')
adam이라는 최적화 알고리즘을 사용하여 가중치를 업데이트합니다.
accuracy를 평가 기준으로 사용하여 모델의 성능을 측정합니다.
sparse_categorical_crossentropy 손실 함수는 다중 분류 문제에 사용됩니다. 이 함수는 실제 레이블과 모델의 예측 사이의 오차를 측정합니다.
4. 인공신경망 학습하기
- early_stop = ~~
이 코드는 초기 중단 기능을 활용하여 검증 손실이 개선되지 않을 때, 학습을 빠르게 중단합니다. 여기서는 10회의 에포크 동안 개선되지 않으면 중단됩니다.
- model.fit(dr.train_X~ callbacks = [early_stop])
fit 메서드를 사용하여 모델을 훈련 데이터로 학습시키며, 검증 데이터로 검증합니다. 또한, 조기 중단 콜백을 사용합니다.
터미널에서 실행시키면 구글 스토리지에서 데이터를 다운로드하기 시작합니다.

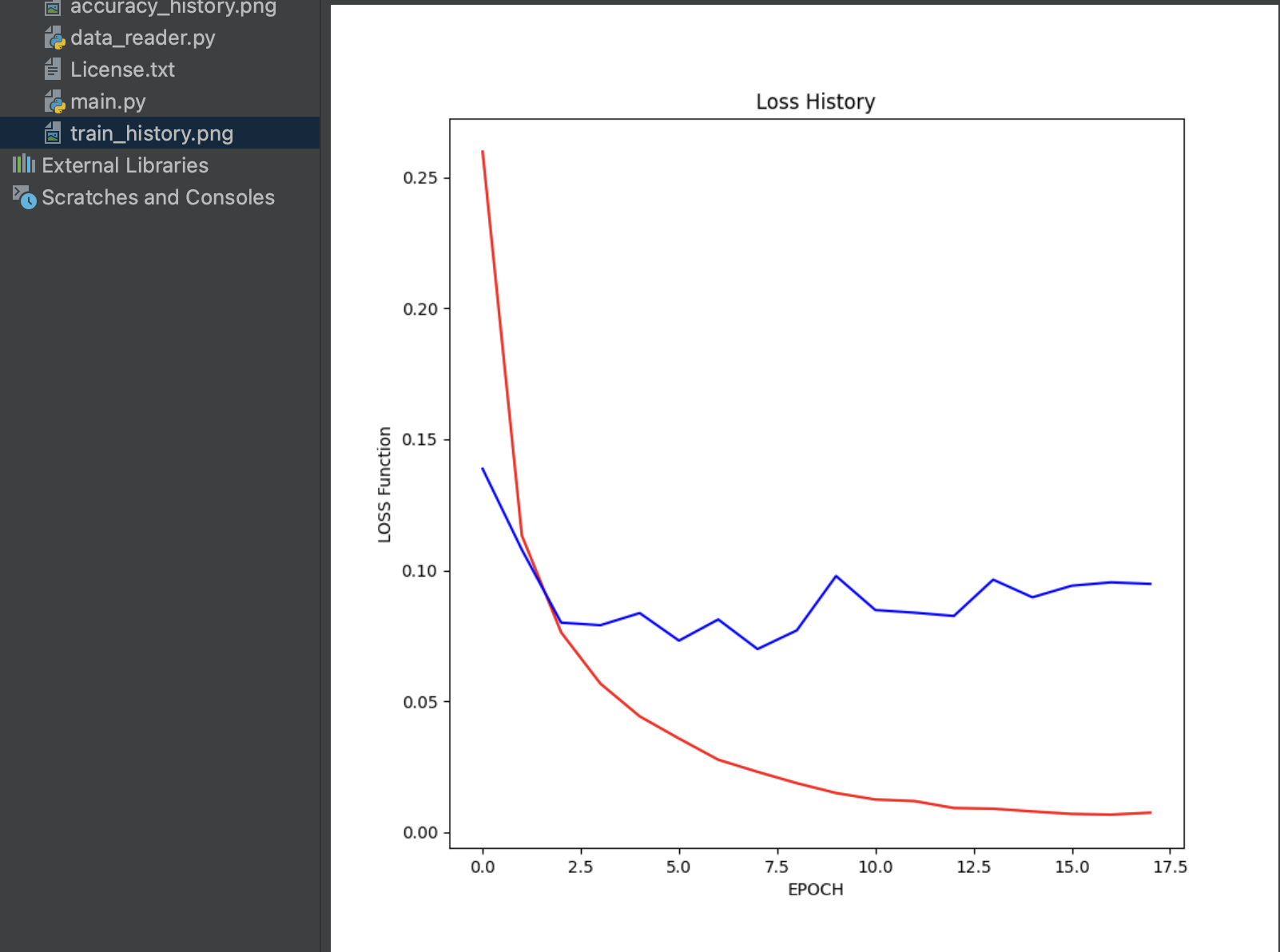
학습 데이터를 시각화하여 살펴보면 엄청나게 overfitting 된다는 사실을 볼 수 있습니다.
Contents
소중한 공감 감사합니다