Web Programming
아키텍쳐 패턴이란? 계층형 아케텍처 패턴의 예시 알아보기 express
- -
728x90
이번 글의 목표
- 아키텍처 패턴의 종류와 각각 장단점을 알아봐요
- 계층형 아키텍처 패턴의 구성 요소를 알아보고 실습합니다
01. 아키텍처 패턴
아키텍처 패턴은 소프트웨어의 구조를 구성하기 위한 기본적인 토대를 제공하는 방법론을 뜻한다.
각각의 시스템들에 역할을 부여하고, 그 사이의 관계와 규칙을 일컬어 말하는 것.
검증된 구조로 개발을 진행하기에 안정적인 개발이 가능함.
복잡한 도메인 문제를 해결하는데 패턴을 사용하면 모델이나 코드를 더 쉽게 변경할 수 있다는 장점이 존재
01.01 대표적인 아키텍처 패턴 : MVC (Model View Controller Pattern)
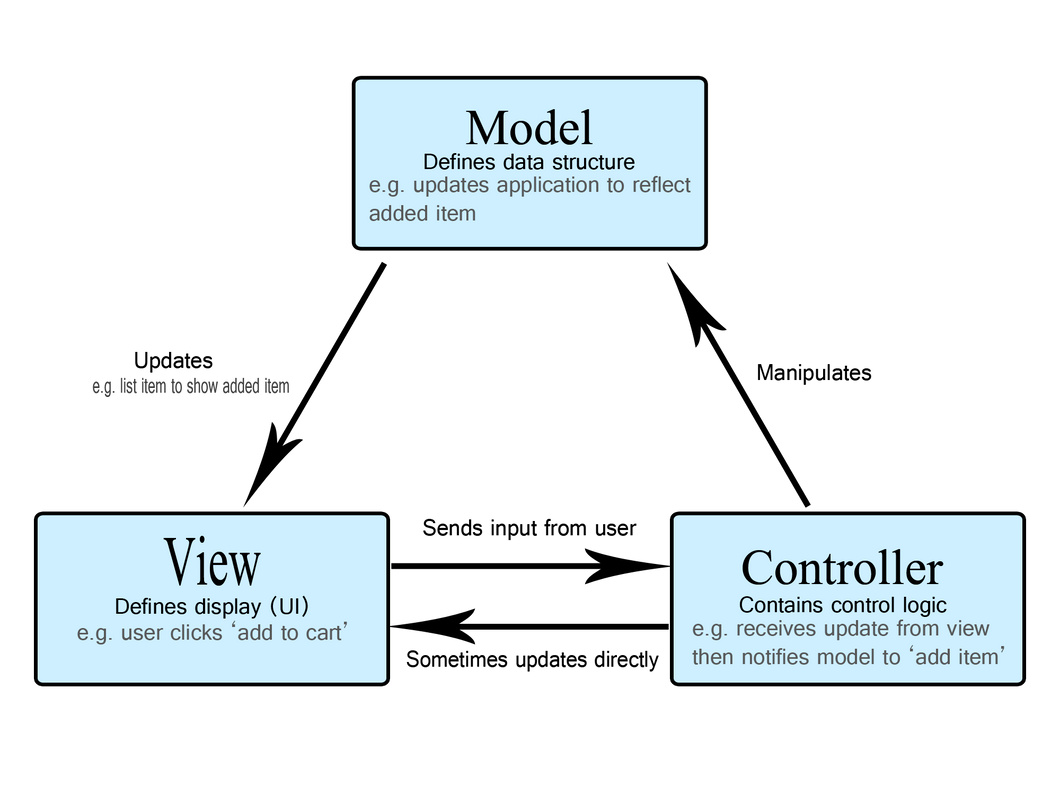
사용자 인터페이스가 많은 애플리케이션에서 많이 사용한다.
모델 : 데이터와 비즈니스 로직을 담당
뷰 : 사용자 인터페이스 담당
컨트롤러 : 클라이언트의 요청을 모델과 뷰로 전달해주는 역할을 담당
01.02 대표적인 아키텍처 패턴2 : 계층형 아키텍처 패턴(Layered Architecture Pattern)

시스템의 서로 다른 기능을 여러 계층으로 분할하는 패턴
일반적으로 컨트롤러, 서비스, 저장소 계층으로 분리하여 사용한다.
01.01 대표적인 아키텍처 패턴 3 : 클린 아키텍처 패턴(Clean Architecture)

소프트웨어를 내부 도메인을 향하는 의존성을 가지는 여러 계층으로 분리하는 패턴
클라이언트의 요청 처리, 데이터 베이스 조작, 외부 시스템과의 통신은 외부 계층에서 처리
소프트웨어의 유지보수성과 확장성을 향상시키는 것이 주 목표
01.01 대표적인 아키텍처 패턴 4 : 마이크로 서비스 아키텍처 패턴(Microservices Architecture Pattern)

특징
- 시스템을 작고, 독립적으로 배포 가능한 서비스로 분할할 수 있다.
- 하나의 시스템에서 다양한 언어와 프레임워크를 도입할 수 있는 패턴
- 서비스 간의 통신은 API 또는 이벤트 기반 아키텍처(EDA, Event Driven Architecture)를 통해 통신
02. 아키텍처 패턴을 도입하기 전에 고민해야 할 사항
- 아키텍처 패턴이 주는 이점과 비용에 대한 이유가 확실해야 한다.
- 해당하는 아키텍처 패턴을 체택했을 때, 어떤 장단점이 존재하는지 명확하게 인지해야 한다.
- 여러 계층을 추가하기 위해 들이는 노력과 시간을 투자할 만한 가치가 있을 정도로 애플리케이션과 도메인이 복잡한 경우에만 아키텍처 패턴을 도입해야 한다.
03. 계층형 아키텍처 패턴 심화 학습
위에서 살펴본 아키텍처 패턴 중에 계층형 패턴은 현재 가장 널리 채택되고 있는 아키텍쳐 패턴 중 하나이기에 좀 더 공부해 보도록 합시다.
단순하고 대중적이어서 비용도 적게 들 뿐더러 모든 애플리케이션의 표준 아키텍처라고 할 수 있습니다. 어떤 아키텍처 패턴을 도입할지 확신이 없을 때에는 계층형 아키텍처 패턴은 좋은 대안이라고 할 수 있습니다.
게층형 아키텍처 패턴은 각 계층을 명확하게 분리해서 유지하고, 각 계층이 자신의 바로 아래 계층에게만 의존하게 만드는 것이 목표입니다.
이렇게 계층을 명확해서 분리해서 상호 의존성을 만드는 '계층화'는 각 계층이 높은 응집도(Cohesion)을 가지며, 다른 계층과는 결합도(Coupling)를 최소화하는 것입니다. 여기서 상위 계층은 하위 계층을 사용할 수 있지만, 하위 계층은 자신이 어떤 상위 게층에 속하는지 알 필요 없이, 독립적으로 동작할 수 있어야 합니다.
예를 들어, 데이터 엑세스 계층은 비즈니스 계층에 어떤 코드가 있는지 알 수 있는 방법이 없고, 사용하면 안 됩니다.

일반적으로 게층형 아키텍처 패턴은 규모가 작은 애플리케이션의 경우 3개의 계층, 크고 복잡한 경우는 그 이상의 계층으로 구성됩니다.
저희는 이제 3 계층 아키텍처의 예시를 살펴보도록 하겠습니다.
03. 3계층 아키텍처로 실제 예시 살펴보기
계층 아키텍처 패턴을 세 개의 계층으로 나눴을 때의 각각의 계층은 아래와 같습니다.
- 프레젠테이션 계층 (Presentation Layer) - Controller : 애플리케이션의 가장 바깥 부분, 요청/응답을 처리 : 클라이언트의 요청(Request)를 수신한 후 서버에서 처리된 결과를 반환(Response)해주는 역할을 담당
- 비즈니스 로직 계층 (Business Logic Layer) - Service : 어플리케이션의 중간 부분, API의 핵심적인 동작이 많이 일어나는 부분 : 아키텍처의 가장 핵심적인 비즈니스 로직이 수행되는 부분입니다.
- 데이터 액세스 계층(Data Access Layer) | 영속 계층 (Persistence Layer) - Repository : 애플리케이션의 가장 안쪽 부분, 데이터베이스와 맞닿아 있음. 실제 데이터베이스와 통신하는 계층이라고 볼 수 있습니다.
아래 계층형 아키텍처의 장점을 상기하며 실습합니다.
- 관심사를 분리하여 현재 구현하려는 코드를 명확하게 인지할 수 있습니다.
- 각 계층은 서로 독립적이며, 이존석잉 낮아 모듈을 교체하더라도 코드 수정이 용이합니다.
- 각 계층별로 단위 테스트를 작성할 수 있어 테스트 코드를 조금 더 용이하게 구성할 수 있습니다.
Layered Architecture에서는 아래의 플로우를 기반으로 로직을 수행합니다.
- 클라이언트가 애플리케이션에 요청을 보낸다.
- 요청을 URL에 따라 알맞은 컨트롤러가 수신을 받는다.
- 컨트롤러는 요청을 처리하기 위해 서비스를 호출한다.
- 서비스는 필요한 데이터를 가져오기 위해 저장소에게 데이터를 요청합니다.
- 서비스는 저장소에서 가져온 데이터를 가공하여 컨트롤러에게 데이터를 전달합니다.
- 컨트롤러는 서비스의 결과물을 클라이언트에게 반환합니다.

컨트롤러의 역할
- 클라이언트의 요청을 받습니다.
- 요청에 대한 처리는 서비스에게 위임합니다.
- 클라이언트에게 응답을 반환합니다
서비스
- 사용자의 요구사항을 처리하는 실세
- 현업에서는 서비스 코드가 계속 확장될 수 있다.
- DB 정보가 필요할 때는 Repository에게 요청한다.
저장소
- 데이터베이스 관리(연결, 해제, 자원관리) 역할을 처리합니다.
- 데이터베이스의 CRUD 작업을 처리합니다.
04. 계층 아키텍처 실습해 보기
프로젝트를 설치합니다.
1. `. env`파일을 만들어 DB 속성을 myql 데이터 베이스에 연결하고 기존 JWT의 키를 설정해 줍니다.
2. yarn 패키지를 설치하고 Prisma로 DB 및 테이블 정보를 동기화해줍니다.
해당 폴더를 아래와 같은 구조로 정리해 봅니다.
내 프로젝트 폴더 이름
├── package.json
├── prisma
│ └── schema.prisma
├── src
│ ├── app.js
│ ├── controllers
│ │ └── posts.controller.js
│ ├── middlewares
│ │ ├── error-handling.middleware.js
│ │ └── log.middleware.js
│ ├── repositories
│ │ └── posts.repository.js
│ ├── routes
│ │ ├── index.js
│ │ └── posts.router.js
│ ├── services
│ │ └── posts.service.js
│ └── utils
│ └── prisma
│ └── index.js
└── yarn.lock
04. 1. 컨트롤러 만들기 (가장 상위의 Presentation Layer 만들기)
presentation layer은 3 계층 아키텍처 패턴에서 가장 먼저 클라이언트의 요청을 만나게 되는 계층이며, 대표적으로 컨트롤러가 이 역할을 담당합니다.
- 하위 계층(서비스 계층, 저장소 계층)에서 발생하는 예외를 처리합니다.
- 클라이언트가 전달한 데이터에 대해 유효성을 검증하는 기능을 수행합니다.
- 클라이언트의 요청을 완료한 후 서버에서 처리한 결과를 반환합니다.
Express에서 컨트롤러와 라우터를 연결하기 위해서는 express.Router을 사용하여 라우터가 클라이언트 요청에서 특정 URL과 HTTP Method를 전달받았을 때 컨트롤러의 특정 메서드로 요청된 내용을 전달하도록 구현해야 합니다.
1. controller 폴더를 src 내에 생성하고, src/posts/post.router.js 에서 연결시켜 줍니다.


여기서 인스턴스를 생성한다는 말의 뜻은 'PostsController 클래스에서 객체를 하나 생성하겠다는 뜻입니다. 클래스의 인스터느스는 그 클래스의 특성(속성과 메서드)을 가진 객체를 뜻합니다.
*자바 스크립트에서는 new ClassName() 형태로 클래스의 인스턴스를 만들 수 있습니다.
2. 포스트 조회 get 엔드포인트를 수정해 보겠습니다.
// 게시글 목록 조회 API 기존 코드
router.get('/', async (req, res) => {
try {
// prisma를 이용하여 모든 게시글을 조회합니다.
// 선택적으로 조회할 필드를 지정합니다.
const posts = await prisma.Posts.findMany({
select: {
postId: true,
title: true,
createdAt: true,
updatedAt: true,
UserId: true,
User: {
select: {
nickname: true,
},
},
},
orderBy: {
createdAt: 'desc', // 작성 날짜 기준 내림차순 정렬
},
});
const formattedPosts = posts.map((post) => ({
postId: post.postId,
userId: post.UserId, // userId를 추가합니다.
title: post.title,
createdAt: post.createdAt,
updatedAt: post.updatedAt,
nickname: post.User ? post.User.nickname : 'Anonymous',
}));
return res.status(200).json({ data: formattedPosts });
} catch (error) {
console.error(error.stack);
return res.status(500).json({ message: '서버 에러', error: error.message });
}
});// 게시글 목록 조회 - 수정 후 API
router.get('/', postsController.getPosts)
//해당 주소로 get 메소드 요청이 들어올 경우,
// postsController.getPosts를 호출하라는 의미
// 즉, 클라이언트의 요청이 들어오면, postsController 클래스에 정의된 getPosts 메서드를 실행하라는 뜻
이렇게 하면, 우리는 전체 게시글 조회를 컨트롤러와 라우터를 연결했다고 볼 수 있습니다.
그러면 다음 단계는 controller 파일을 작성하여 컨트롤러를 구현하는 것입니다.
src/controllers/posts.controller.js에 아래와 같이 작성합니다.
import { PostsService } from '../services/posts.service.js';
// Post의 컨트롤러(Controller)역할을 하는 클래스
export class PostsController {
postsService = new PostsService(); // Post 서비스를 클래스를 컨트롤러 클래스의 멤버 변수로 할당합니다.
getPosts = async (req, res, next) => {
try {
// 서비스 계층에 구현된 findAllPosts 로직을 실행합니다.
const posts = await this.postsService.findAllPosts();
return res.status(200).json({ data: posts });
} catch (err) {
next(err);
}
};
}ro 이렇게 작성하면, PostsController 클래스에서 게시글 조회 메서드가 완성됩니다.
여기서 await this.postsService.findAllPosts();는 PostsController 클래스의 postService 인스턴스에서 findAllPost 메서드를 호출합니다.
이제 컨트롤러는 전달된 요청을 처리하기 위해 PostsService를 호출하도록 구현되었습니다. 여기서 컨트롤러가 직접 로직을 수행하지 않고, 클라이언트의 요청을 서비스 계층으로 바로 전달하도록 구현한 것을 확인할 수 있습니다.
여기서 아직까지 서비스가 어떤 역할을 하는지는 중요하지 않습니다. 외부에 공개된 메서드를 호출만 하기 때문입니다. 이가 가능한 이유는 추상화(Abstraction) 때문입니다.
04. 2. Service Layer 만들기 (Business Loigic Layer 만드는 법)
서비스 계층이란 다른 이름으로는 비즈니스 로직 계층이라 합니다. 아키텍처의 가장 핵심적인 비즈니스 로직을 수행하고, 클라이언트가 원하는 요구사항을 구현하는 계층이라 할 수 있습니다.
- 프레젠테이션 계층과 데이터 액세스 계층 사이에서 중간다리 역할을 하며, 서로 다른 두 계층이 직접 통신하지 않게 만들어줍니다.
- 서비스 데이터가 필요할 때, 저장소에게 데이터를 요청합니다.
- 애플리케이션 규모가 커질수록 서비스게층의 역할과 코드의 복잡성도 점점 커지게 됩니다.
왜 기존 라우터 단일 파일로 처리하지 않는가?
- 사용자의 유즈케이스와 워크플로우를 명확히 정의하고 이해할 수 있도록 도와줍니다.
- 비즈니스 로직이 API 뒤에 숨겨져 있으므로, 서비스 계층의 코드를 자유롭게 수정하거나 리팩터링 할 수 있습니다.
- 저장소 패턴 및 가짜 저장소와 조합하면 높은 수준의 테스트를 작성할 수 있습니다.
코드 작성
새롭게 src 폴더에 services 폴더를 만들고, posts.service.js를 만들어 준 후 아래 코드를 작성합니다.
// src/services/posts.service.js
import { PostsRepository } from '../repositories/posts.repository.js';
export class PostsService {
postsRepository = new PostsRepository();
findAllPosts = async () => {
// 저장소(Repository)에게 데이터를 요청합니다.
const posts = await this.postsRepository.findAllPosts();
// 호출한 Post들을 가장 최신 게시글 부터 정렬합니다.
posts.sort((a, b) => {
return b.createdAt - a.createdAt;
});
// 비즈니스 로직을 수행한 후 사용자에게 보여줄 데이터를 가공합니다.
return posts.map((post) => {
return {
postId: post.postId,
nickname: post.nickname,
title: post.title,
createdAt: post.createdAt,
updatedAt: post.updatedAt,
};
});
};
}이전에는 Postcontroller 클래스가 클라이언트의 요청을 PostsService 클래스에게 전달하는 과정이었다면,
이번에는 서비스 계층에서 비즈니스 로직을 어떻게 수행하고 필요한 데이터를 어떻게 저장소에 요청하는지를 작성한 것입니다.
코드를 보면 서비스계층에서 PostService 클래스가 PostsRepository의 findAllPosts 메서드를 호출하는 걸 볼 수 있습니다. 해당 코드는 서비스가 비즈니스 로직을 수행하는 데 필요한 데이터를 저장소 계층에서 가져오는 과정입니다.
또한 서비스 과정에서는 posts.sort((a, b) => { return b.createdAt - a.createdAt}처럼 데이터를 가공하는 과정을 거칠 수 있습니다.
04. 3. 저장소 계층 (Data Access Layer) 만드는 법
- 저장소 계층은 데이터 접근과 관련된 세부 사항을 숨기는 동시에, 메모리상에 데이터가 존재하는 것처럼 가정하여 코드를 구현하게 됩니다.
- 저장소 계층을 도입하면, 데이터 저장 방법을 더욱 쉽게 변경할 수 있고, 테스트 코드 작성 시 가짜 저장소를 제공하기 더 쉬워집니다.
- 애플리케이션의 다른 계층들은 저장소의 세부 구현 방식에 대해 알지 못하더라도 해당 기능을 사용할 수 있습니다. 즉, 저장소 계층의 변경 사항이 다른 계층에 영향을 주지 않습니다.
- 저장소 계층은 데이터 저장소를 간단히 추상화한 것으로, 이 계층을 통해 모델 계층과 데이터 계층을 명확하게 분리할 수 있습니다.
- 저장소 계층에 ORM을 사용하면, 필요할 때, MySQL나 Postgres와 같은 다른 데이터 베이스로 쉽게 전환할 수 있습니다.
코드 작성
이전에 작성했던 코드에서 서비스 계층(Service Layer)인 PostsServices에서 PostsRepository를 호출하여 데이터를 요청하는 것을 확인할 수 있었습니다.
이번에는 저장소 계층에서 어떻게 데이터 베이스를 가져와 상위 계층에게 반환하는지 확인해 보도록 하겠습니다.
// src/repositories/posts.repository.js
import { prisma } from '../utils/prisma/index.js';
export class PostsRepository {
findAllPosts = async () => {
// ORM인 Prisma에서 Posts 모델의 findMany 메서드를 사용해 데이터를 요청합니다.
const posts = await prisma.posts.findMany();
return posts;
};
};'Web Programming' 카테고리의 다른 글
| Node.js | Async / Await의 등장배경과 사용 활용법 (0) | 2023.08.28 |
|---|---|
| Node.js 기초 | `request`, `response` 객체를 알아보자 (0) | 2023.08.27 |
| API와 REST API의 개념 | 자바스크립트 예시 (1) | 2023.08.25 |
| Node.js 기초 | 한 장으로 보는 Node.js 특징 (0) | 2023.08.25 |
| Node.js 기초 | 웹 서버란? (0) | 2023.08.25 |
Contents
소중한 공감 감사합니다